
External Player - 哔哩哔哩嵌入式外链播放器
vLLM(Vectorized Large Language Model) 是由加州大学伯克利分校提出的一种高性能大语言模型推理框架,专为提升 LLaMA、ChatGLM、Phi-3 等主流开源模型的推理效率而设计。
它通过一种名为 PagedAttention 的核心技术,在保持生成质量的同时大幅提升推理速度和资源利用率。
vLLM 的核心特性
1. PagedAttention:类比操作系统的内存分页机制
原理:
- 每个序列的 Key/Value 缓存被分割成多个“块”(Page)
- 块之间通过指针链接,实现非连续存储
- 类似操作系统中的虚拟内存管理
优势:
- 支持变长序列批处理
- 显存利用率提高 24% 以上
- 更好的支持并发推理
一、WSL (Windows S链接ubsystem for Linux) 安装 或 Linux
打开启用 cpu 虚拟化
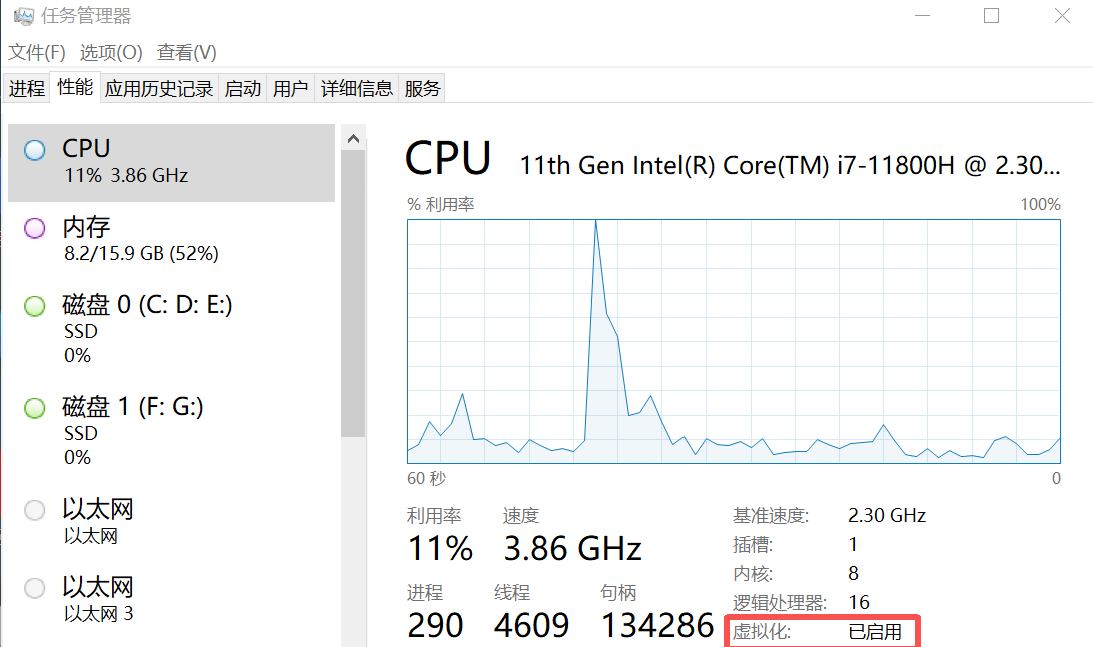
启用 适用于 Linux 的 Windows 子系统 和 虚拟机平台
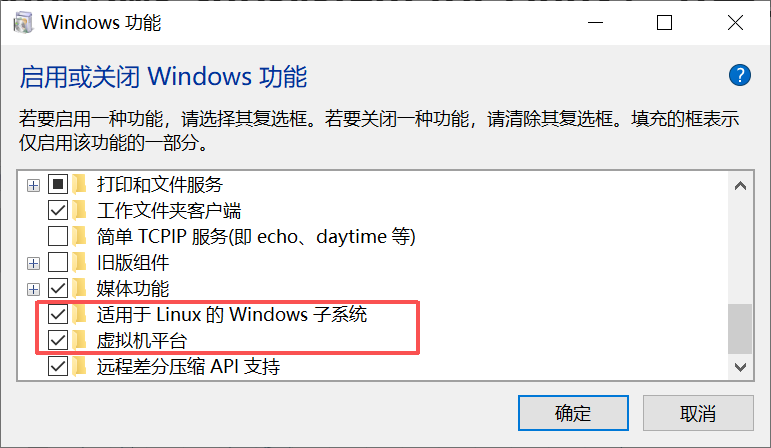
wsl --install
wsl --list --online 查看可以安装的列表
wsl --install Ubuntu-24.04 安装稳定版Ubuntu系统
wsl --list -verbose 查看已安装的系统
wsl --shutdown 关闭所有WSL实例,确保数据一致性,再次运行 wsl -l -v确认状态为 Stopped
wsl --export Ubuntu-24.04 G:\Ai\WSL\ubuntu_backup.tar 迁移到G:\Ai\WSL\
wsl --unregister Ubuntu-24.04 删除C盘上的原发行版
wsl --import Ubuntu-24.04 G:\Ai\WSL\Ubuntu G:\Ai\WSL\ubuntu_backup.tar --version 2 将备份文件导入到目标磁盘
del G:\Ai\WSL\ubuntu_backup.tar 确认迁移成功后,删除.tar备份文件释放空间

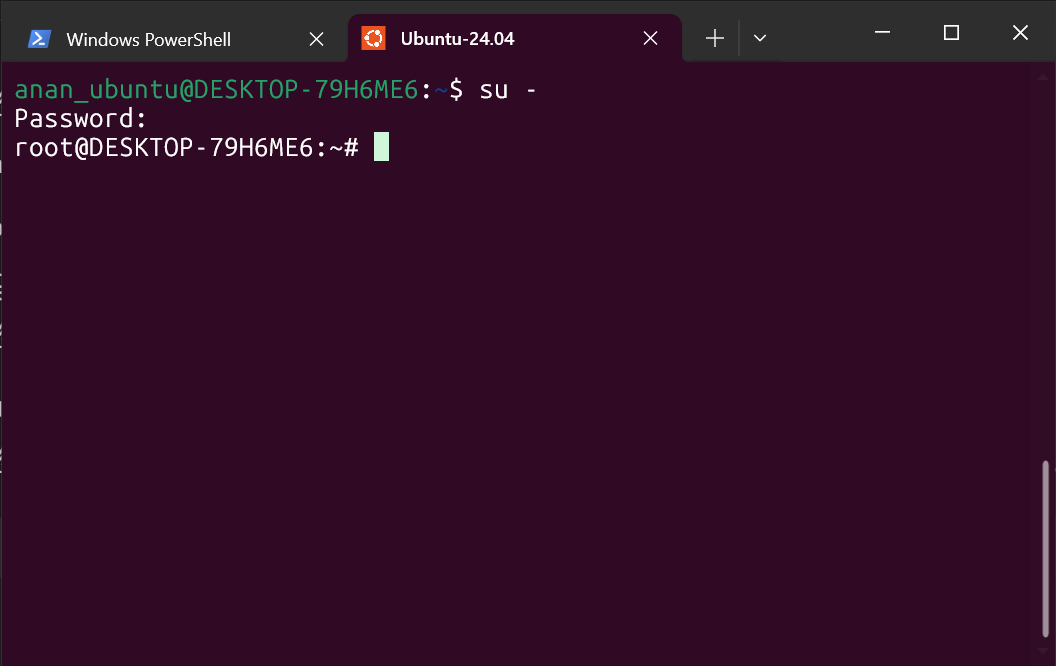
二、切换至 root 用户
su -
三、更新软件包
sudo apt update && sudo apt upgrade
四、安装 Python
4.1Python 安装
sudo apt upgrade python3
4.2pip 安装
sudo apt install python3-pip
4.3venv 安装
sudo apt install python3-venv
4.4pip 镜像设置
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip config list
五、创建 vllm 项目目录
mkdir -p code/vllm_deploy
cd code/vllm_deploy
六、虚拟环境设置
python3 -m venv .venv
source .venv/bin/activate
七、安装依赖
pip install "vllm>=0.11.0"
pip install "qwen-vl-utils==0.0.14"
pip install modelscope
八、模型下载
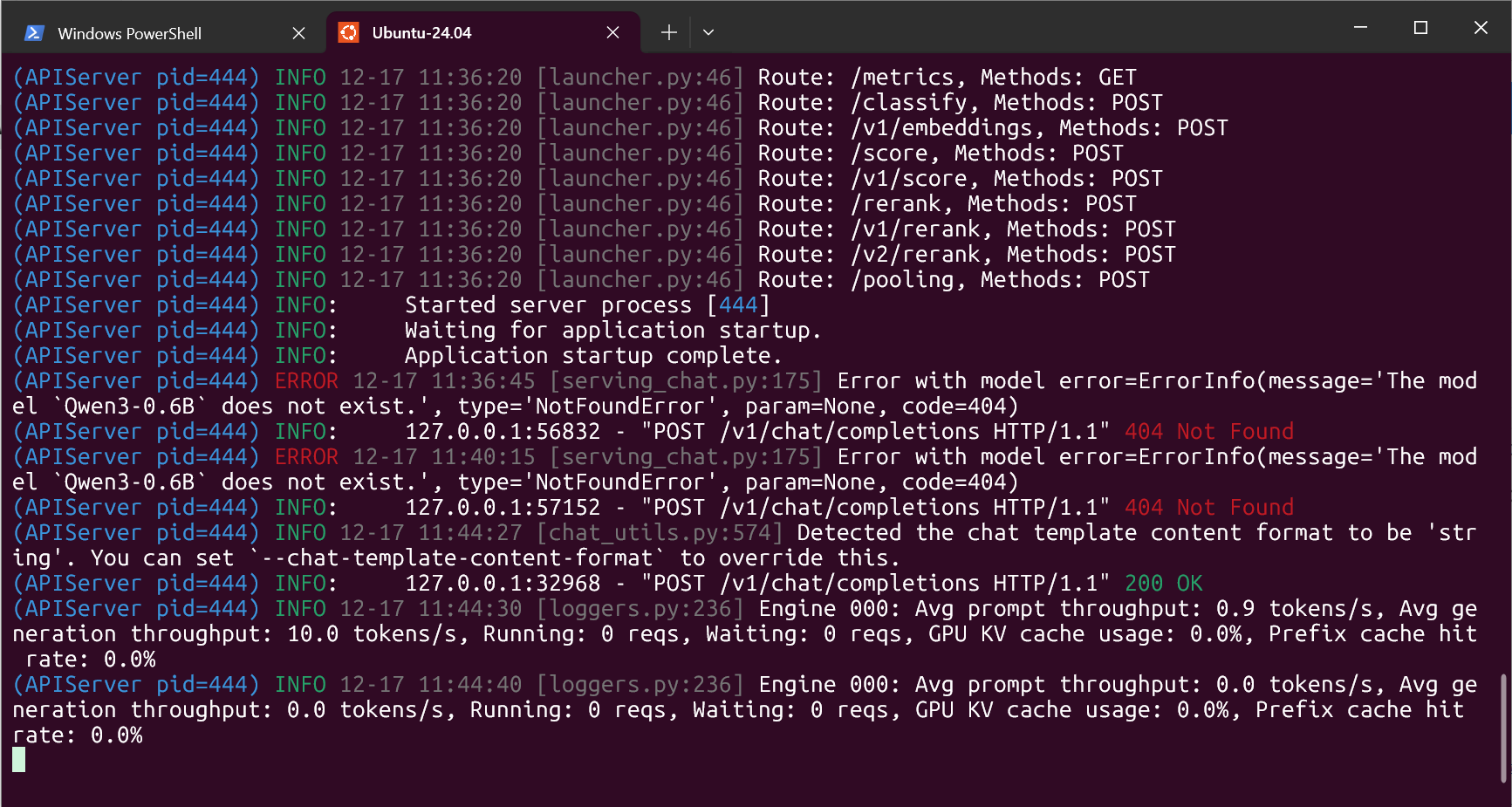
modelscope download --model Qwen/Qwen3-0.6B --local_dir Qwen/Qwen3-0.6B
九、启动
先激活虚拟环境(source .venv/bin/activate)
vllm serve Qwen/Qwen3-0.6B \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 1024 \
--gpu-memory-utilization 0.6 \
--dtype float16 \
--max-num-seqs 4 \
--trust-remote-code
| 参数 | 说明 | 针对6GB显存的优化作用 |
|---|---|---|
| –gpu-memory-utilization 0.6 | 设定vLLM可使用的GPU显存比例。 | 将可用显存限制在约3.6GB,为系统、WSL和其他进程预留充足空间,是防止因显存被完全占用导致启动失败的最关键参数。 |
| –max-model-len 1024 | 限制单个请求的输入和输出总Token数。 | 大幅降低KV Cache(键值缓存)的显存占用。上下文长度是影响长文本处理时显存需求的关键因素,适当降低此值能有效减少内存压力。 |
| –max-num-seqs 4 | 控制同时处理的请求数量(并发数)。 | 降低系统并发处理的峰值显存压力,避免因多个请求同时处理而导致显存溢出(OOM)。 |
| –dtype float16 | 指定模型推理时使用的数据精度。 | 使用半精度浮点数,能在保证模型性能的同时,减少显存占用。 |
| –trust-remote-code | 允许加载模型的自定义代码。 | 对于Qwen等使用了自定义架构的模型,此参数是必须的,以确保能正确解析和加载模型。 |
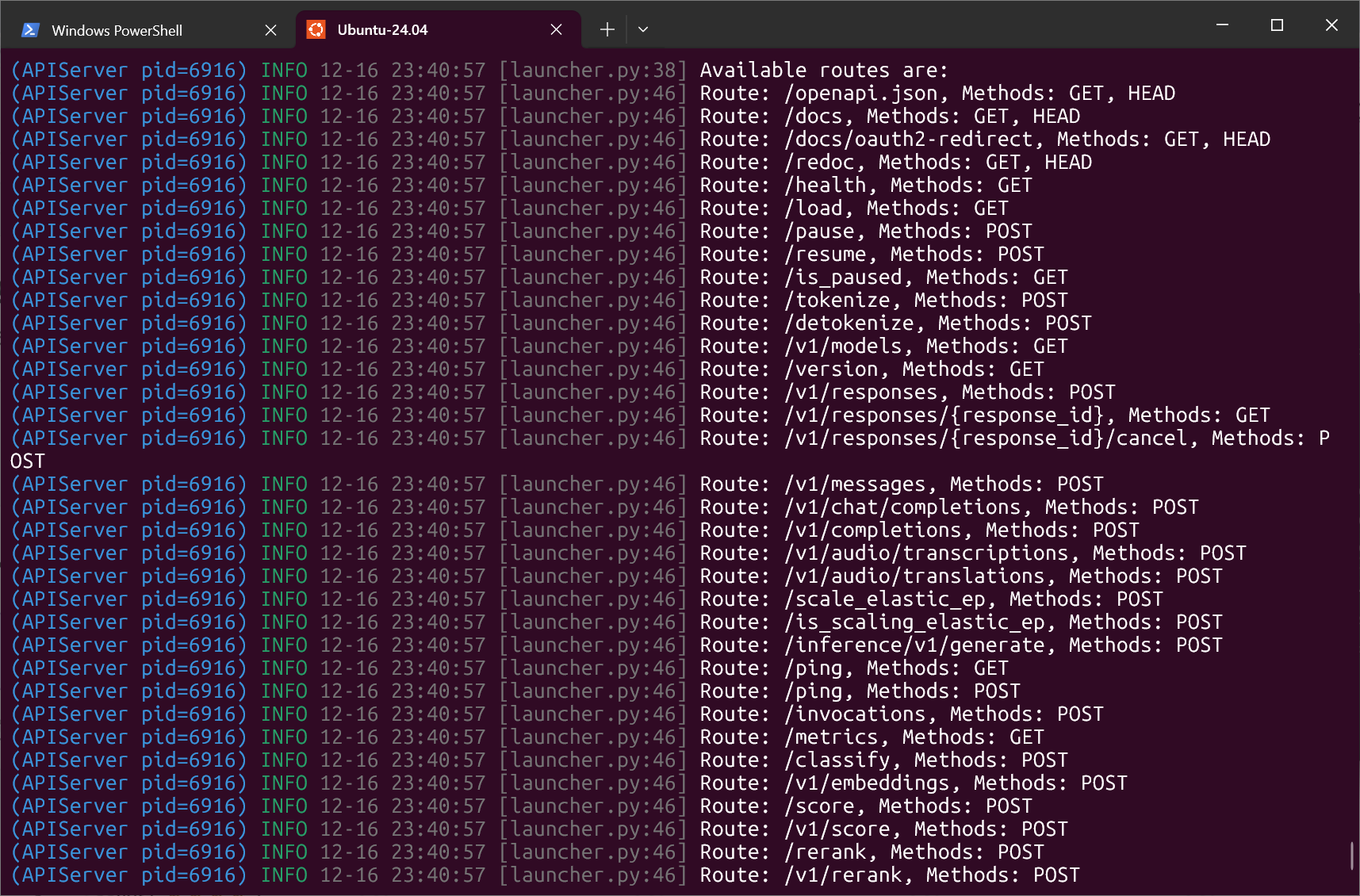
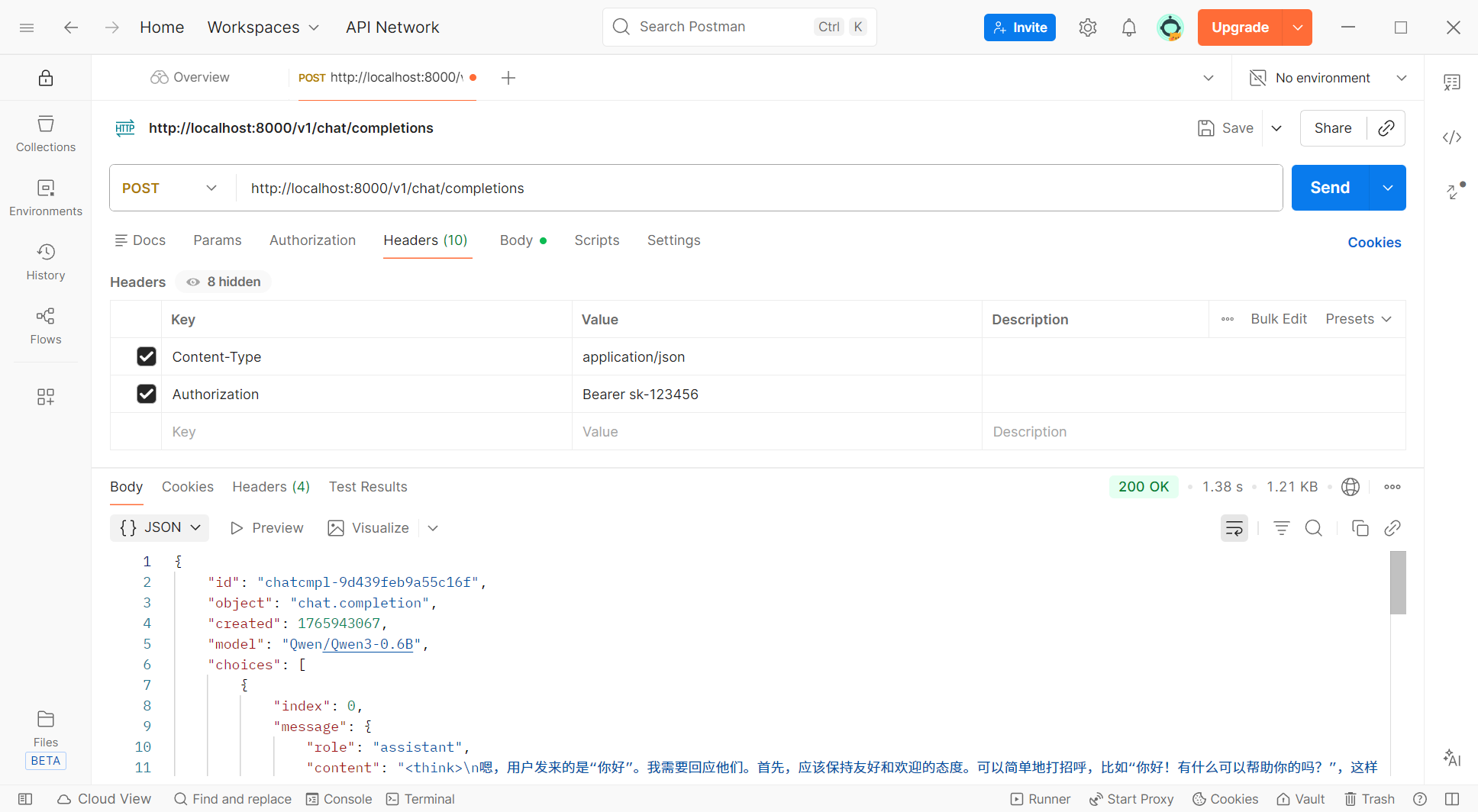
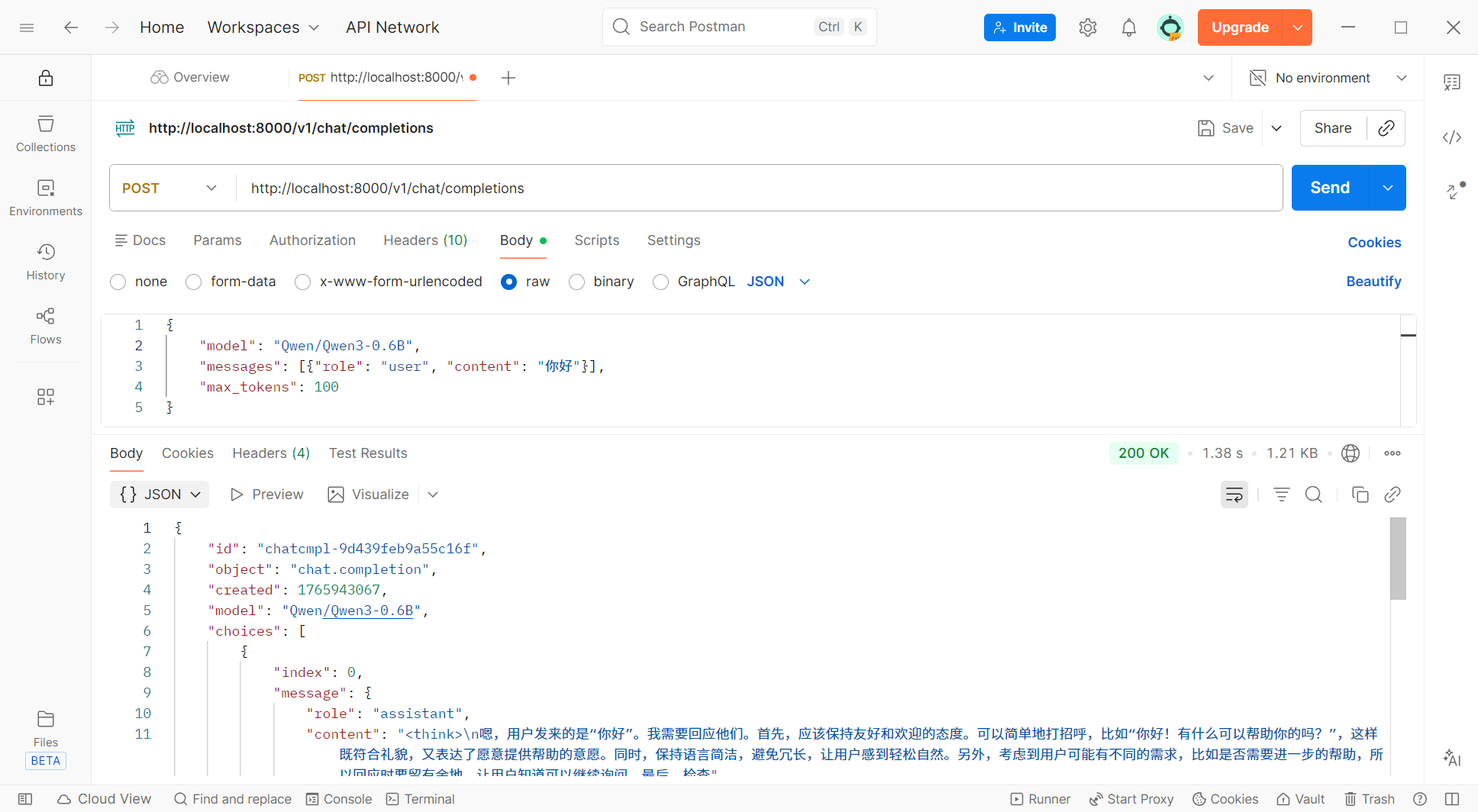
十、接口测试
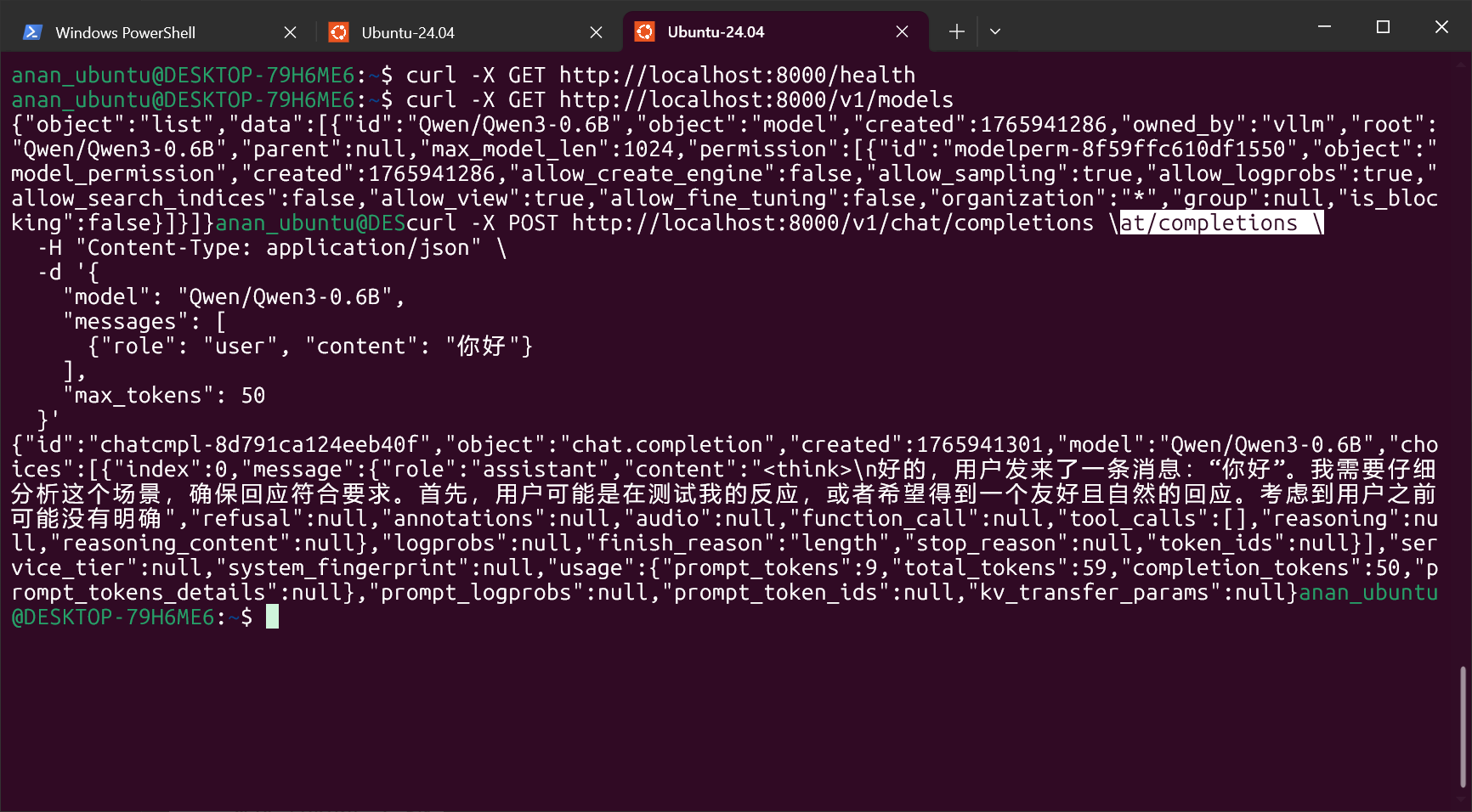
curl:
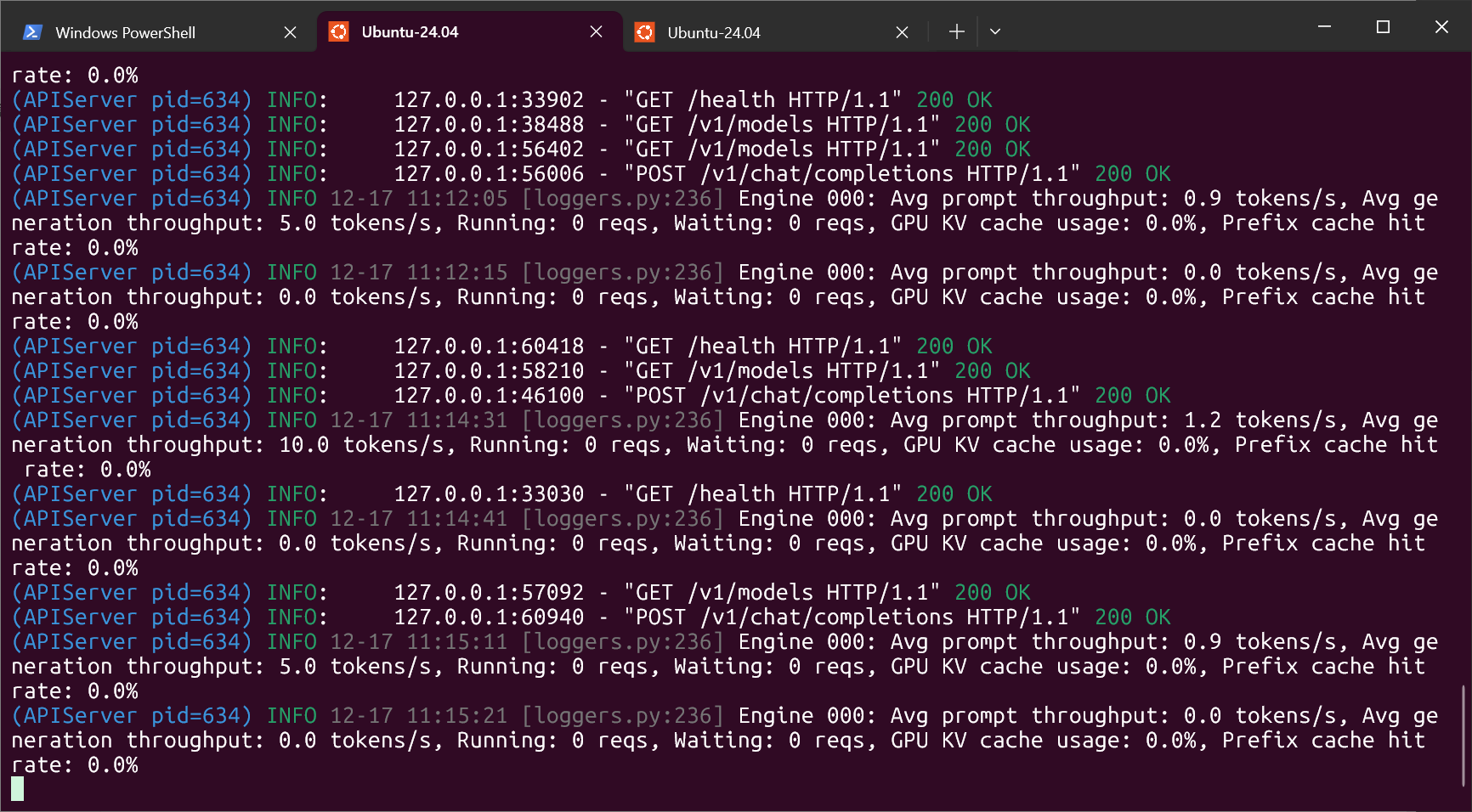
postman:
const language = "typescript";